Introduction
There are countless articles on DynamoDB qua NoSQL, a distributed DB, a high-level comparison to other technologies, and a serverless DB. This is not one of those posts.
The disconnect between AWS DynamoDB marketing and real-world use-cases has led many engineers (including myself) to burn cycles trying to force a solution into DynamoDB, when no such solution exists.
This article closes the gap between AWS DynamoDB documentation and non-demo requirements (real-world applications/systems). How? By presenting a collection of use-cases, limitations, gotchas, and most importantly, do-not-use-cases from the wild (enterprise software).
The audience? Software engineers, architects, developers, CTOs, et al., who must decide on a data storage and access approach for an application (or platform/system).
At the end of this article, we will be able to decisively specify if DynamoDB is the right solution for our use-cases.
Note well, you can skip straight to the limitations without any preamble.
Table of Contents
Introduction
DynamoDB Overview
The Benefits of DynamoDB
The Limitations of DynamoDB
The Annoyances of DynamoDB
Summary
DynamoDB Overview
For our purposes, we will focus on the design of DynamoDB as a hash table. We can display some important limitations without even mentioning oft-highlighted features of DynamoDB as a distributed, serverless, NoSQL database service.
So, what is a hash table? Further, how does DynamoDB simulate a hash table?
Hash Tables
The hash table is frequently encountered because of its a power for many use-cases. Hash tables underpin much of our commonly used software constructs (objects/dictionaries, arrays, queues/stacks, etc.).
A hash table stores data associated with keys, evenly distributed across a storage space, which facilitates constant-time retrievals by key.
Along with the following diagram, let us walk through the read and write operations for a hash table. This will give us two takeaways we can apply to DynamoDB.
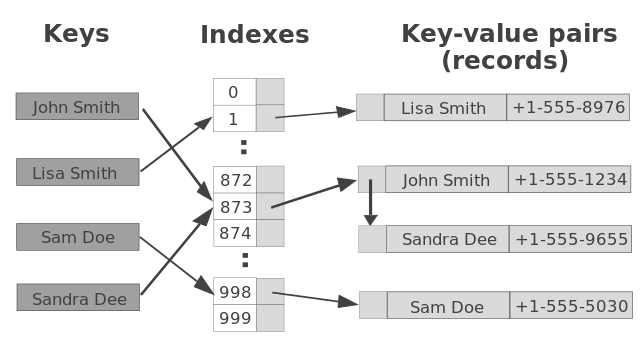
Writing to a Hash Table
1. Give a hash table a key (and an optional value)
In the example above, the key is a name.
2. Key is hashed into a hash key
Important point: hash keys are evenly distributed across the hash table storage space.
In the diagram above, the hash keys are numeric indexes into buckets of key value pairs.
3. Key and value are stored with the hash key in a bucket within the storage space
Because each bucket is the same maximum size, if the hashing algorithm does its job correctly, then the keys are distributed evenly across the buckets (over time). This write operation is computationally heavy if the write triggers the hash table to resize and reinsert all items (if it runs out of buckets/bucket space). But, we take this processing hit on write so that we can read from the hash table with minimal processing.
Reading from a Hash Table
1. Give a hash table a key
In the example diagram above, the lookup key is a name.
2. Key is hashed into a hash key
In our example, the hash key is a numeric index that maps to a key-value pair record.
3. Hash key is used to retrieve record from correct bucket
4. Value(s) from bucket returned
Now we are in a position to extract our two takeaways — a payoff and a rub.
The Payoff
If you know the key of the data you are requesting, a retrieval operation from a hash table is amortized to constant time complexity. Doesn’t matter how big the data, if you know the key, you get the data fast.
The Rub
If you do NOT know the key of the data you are requesting, a retrieval operation from a hash table is linear time complexity. Without the key to look up the value, the entire table must be scanned to find the requisite data.
Some readers will probably see the thrust of the argument developing. We can develop it by tying the payoff of a hash table to DynamoDB’s best use-case. Then, we can move from the rub of using a hash table to DynamoDB’s limitations.
DynamoDB as a Hash Table
Much of the power of DynamoDB comes from two design choices made by AWS.
(1) use a glorified hash table
(2) distribute the hash table across database servers
(1) allows DynamoDB to partition data into evenly distributed buckets that can be queried in near constant-time when provided retrieval keys (partition key and optional sort key).
(2) allows DynamoDB to replicate, scale, and lookup data based on partitions of data on different servers
How does DynamoDB do this?
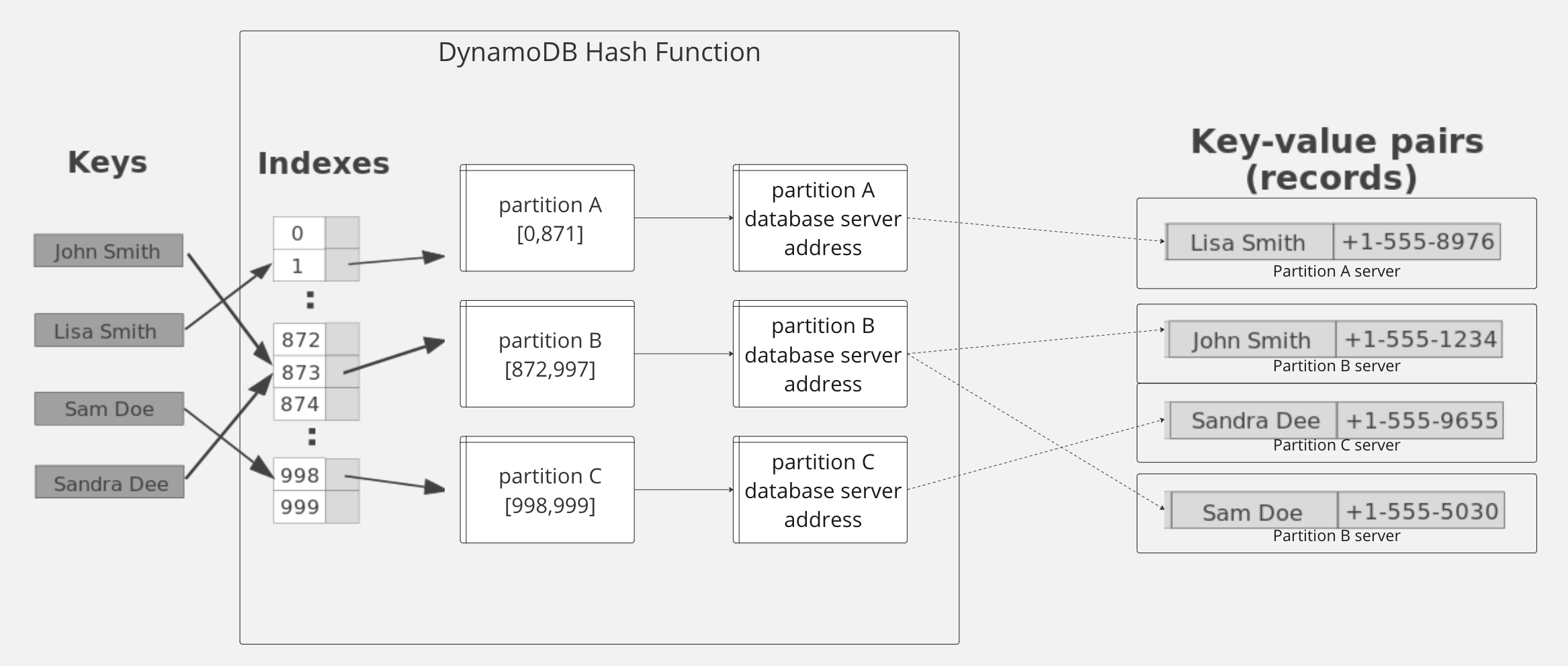
At the highest level, the DynamoDB hashing algorithm (simplification) adds some magic to the regular hash table hashing algorithms. The flow is as follows:
Given a partition key and (optional) sort key…
- Hash the keys into a hash key
- Lookup the relevant partition using the hash key
- instead of an in-memory location reference (via a numeric index), the partition lookup provides an internet location reference to access the partition from a remote server
- Once the partition on the remote server is queried, all further data querying/manipulation gets a performance boost by already having access to the given partition data (same server location)
- Within the partition, look up the relevant items via sort key
The result is near constant time queries regardless of the size of data in the DynamoDB table.
Similar to the hash table data structure, if the use-case is querying via a known key, DynamoDB is well-suited. In fact, DynamoDB is wonderfully snappy for this access pattern.
However, also similar to the hash table data structure, if the use-case requires querying based on data attributes other than partition and sort key, DynamoDB is not the right choice of technology. Why?
If you need to access data but don’t know where to find it (partition/sort key), DynamoDB must scan the entire table. The scan operation is a heavy processing cost — at least linear relative to the number of items in the table. As the table size grows, the scan operation time complexity grows in direct proportion.
So, how do we use DynamoDB to retrieve data efficiently? There are two primary options: (1) overload partition/sort keys, and/or (2) use secondary indexes.
Overloading Partition and Sort Keys
We can avoid scanning our table by overloading partition and sort keys. For example, we can have a base partition key of AD# for our table. AD# represents an advertisement partition in our table. Assuming we have an advertisement ID, we can query for the items in that ad partition by using AD#example_ad_id.
In the following example table, we see advertisements partitioned by their IDs.

Notice, for each advertisement partition, we can store data for each week the advertisement was broadcast by using the broadcast week as a sort key. This technique allows us to query for a slice of broadcast week data for a given advertisement. For example:
partition_key = AD#example_ad_id_1 AND sort_key BETWEEN BW#example_broadcast_week_1 AND BW#example_broadcast_week_3
Now, assume we want to query the rollup of spend values for all the broadcast weeks a single advertisement runs. In order to do this, we overload the sort key. Overloading the sort key for advertisements facilitates querying for different types of advertisement data from the same advertisement partition.
Let’s overload the sort key with a new key AD_SUMMARY. N.B., the combination of partition key and sort key must occur only once in the table.
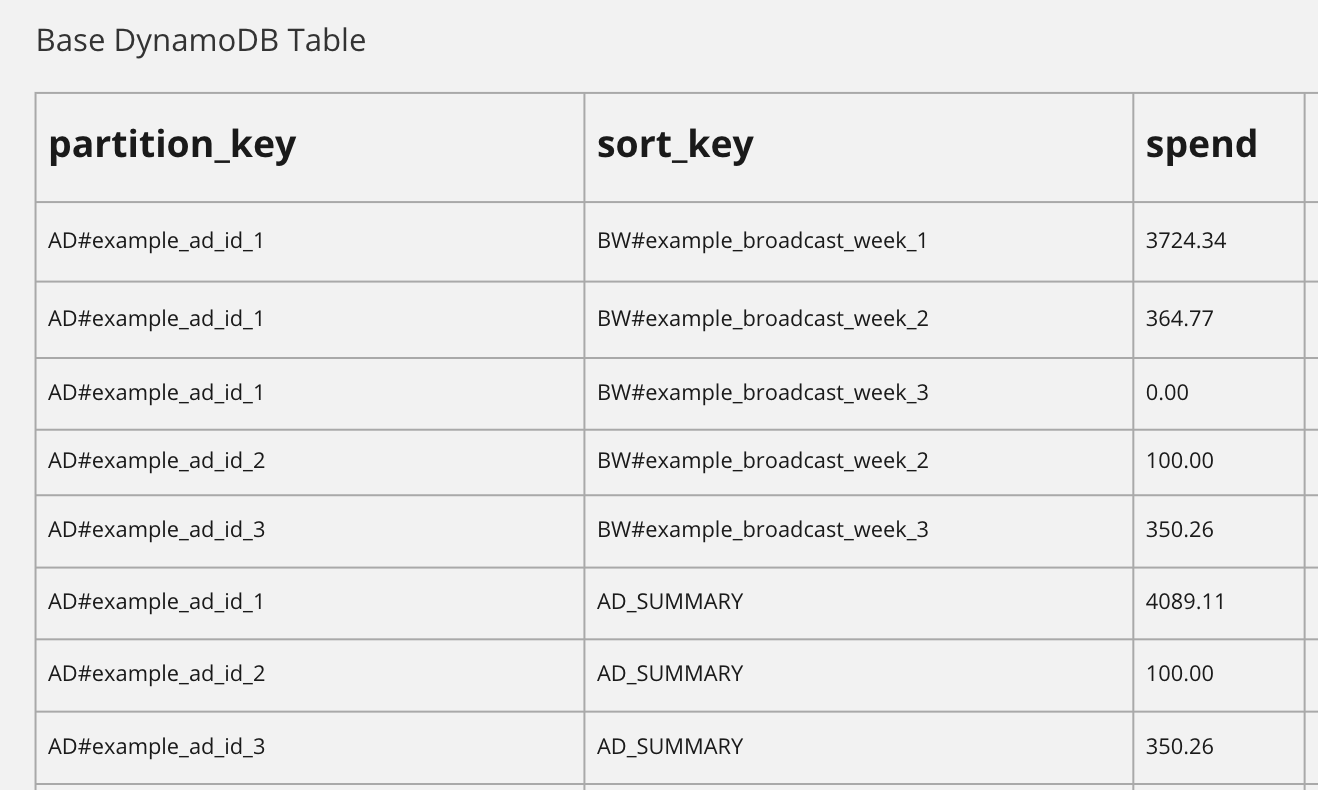
Now we can query the total spend of an advertisement, for example:
partition_key = AD#example_ad_id_1 AND sort_key = AD_SUMMARY
This query will give us the pre-calculated summary data for an advertisement. Cool.
Now, let’s slice the table again by overloading the partition key.
Let’s assume we want to store companies in our table. We could overload the partition key by creating a COMP# partition. Now, we can query for a company using a partition key COMP#example_company_id. By overloading the partition key, we can create multiple partitions within the same table.
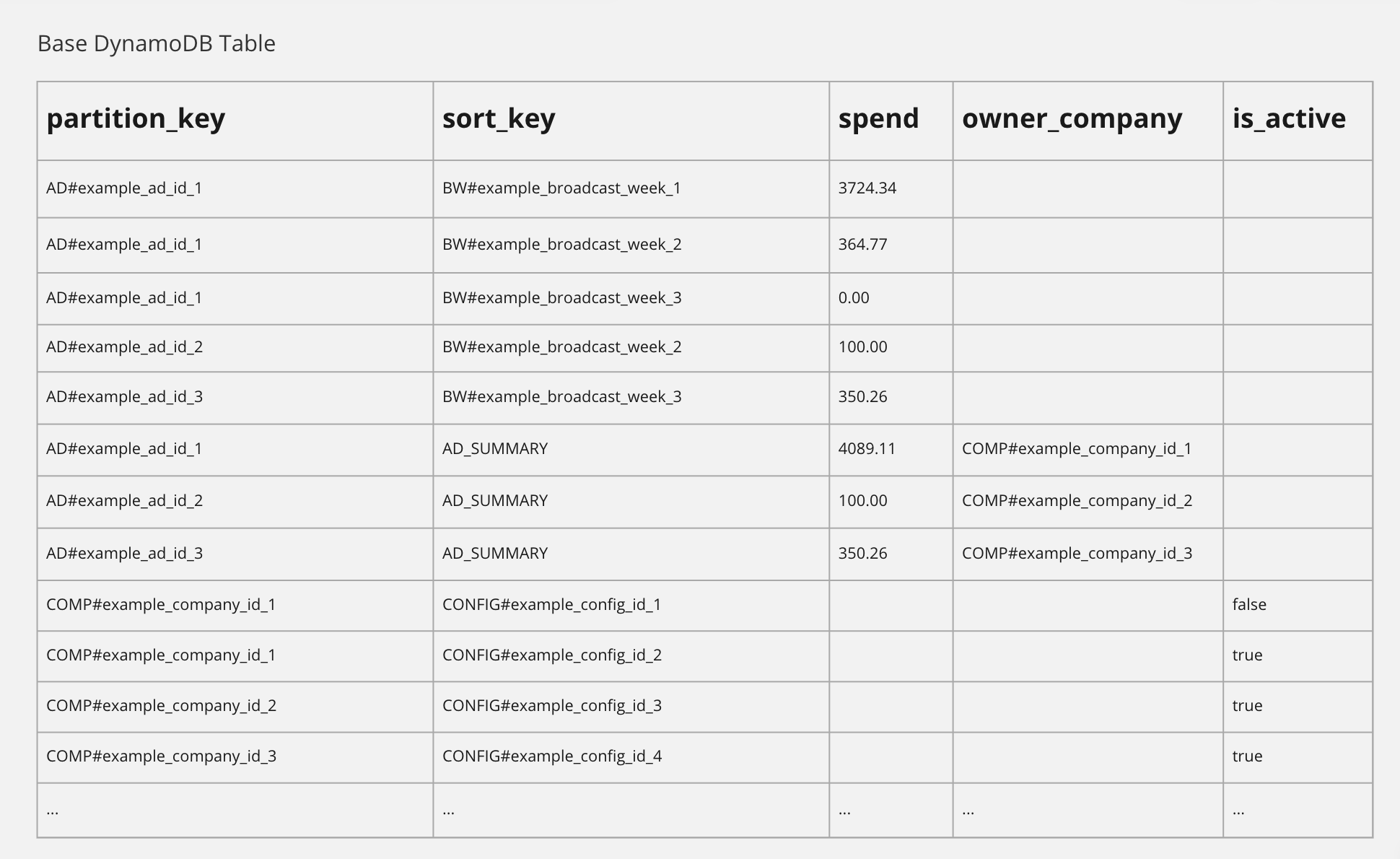
We have seen how we overload partition and sort keys within a table to support desired access patterns. Simple access patterns of relatively static (unconnected) data. What if we need to support a different access pattern? For example, we shall assume that given a company ID, we need to retrieve all of the advertisement summaries owned by the company. Our current table design will not support this type of query, as we do not know the partition keys of all the advertisements associated with a company. We would require a table scan operation to collect all of the relevant advertisements. Obviously, this is unacceptable for many applications.
DynamoDB solves this access pattern with their Global Secondary Indexes (GSI).
A GSI for a table allows us to efficiently query the same data from our table, but using a different partition/sort key; thus, avoiding the scan operation. Let’s take a look at GSIs.
Global Secondary Indexes
A GSI will automatically write relevant data from the base table into an index, rotated to use a different partition/sort key. Then, we can query the GSI using the desired partition/sort key. Let’s dive in to our example.
Reminder, we want to lookup all of the advertisement summaries associated with a given company. Since the company ID is not a primary/sort key for advertisement summaries on the base table, we will be unable to query. So, we create a GSI on our base table.
The GSI has a partition key of owner_company. The sort key is the base table’s partition_key.

As we see above, any item in our base table with an owner_company value will get written to the index using the value as the partition key and the advertisement ID (base table partition_key) gets rotated to the index sort key. We can specify which columns to include in the GSI. We included the spend for each ad summary.
Here is the beauty of the GSI we set up. We now have a partition for each company that we can query. We can get all of the advertisement summaries associated with example company 1 by querying as follows:
// query to GSI, not base table owner_company = COMP#example_company_id_1
We covered quite a bit of material. We are ready to see the point — the use-cases that benefit from DynamoDB and the do-not-use-cases where the limitations of DynamoDB make it a poor choice.
Benefits of DynamoDB
The Sweet Spot(s)
DynamoDB is a fantastic choice for use-cases with the following characteristics:
- access pattern is known
- access patterns will not be added in the future
- data is static
- data is minimally related
- data lends itself to pre-calculation
- minimal sorting and filtering
- no ad hoc data access requirements
- minimal requirements for aggregated and computed data
Let us validate our example use case outlined above:
(1) we know the access pattern — we take a company ID and retrieve all associated advertisement summaries
(2) assume for this use-case that no other access patterns will be added in the future
(3) data is relatively static — each week the table/index gets updated with new data
(4) data is minimally related (simple) — company has_many advertisements
(5) data lends itself to pre-calculation — advertisement summaries are easily pre-calculated from all advertisement broadcast weeks
(6) minimal sorting and filtering — let’s assume that the sorting and filtering requirements are merely to return the associated advertisements in any order
(7) no ad hoc access patterns — we only support query by company id and that’s it
(8) the pre-calculated rollups of advertisements over time into a summary of aggregated spend is simple
All of these assumptions about our use-case are unlikely to stand up to real-world requirements. So, let’s add some requirements to highlight the limitations of DynamoDB.
Limitations of DynamoDB
In my experience, I have found some severe limitations to using DynamoDB for many enterprise use-cases. I will display these limitations by adding some new requirements to our above example.
We will focus upon three primary limitations:
- lack of flexibility
- lack of extendability
- lack of DB-layer aggregate operations
All three of these limitations will be highlighted in our subsequent examples.
First Contact with the Enemy (New Requirements)
Everyone has a plan until they get punched in the mouth.
— Mike Tyson
When building real-world software, requirements change. When extending software, requirements have been added. When using enterprise SaaS products, we expect the ability to interact with our data in sensible ways, like filtering and sorting.
These somewhat uncontentious assertions raise significant doubts about DynamoDB as a technology choice beyond a narrow set of use-cases. If we are unable to change requirements, add functionality, and create functionality that meets baseline-expectations using DynamoDB, we want to know that upfront.
Suppose our team gets the following change request: the advertisements must be sorted by highest spend.
Fair enough. Easy change. We already have the advertisement summaries by associated company with the total spend for that advertisement. When we are doing the total spend rollup (outside DynamoDB), we need to add a sorting process. Once we have the advertisement summaries, each with total spend, we can sort on the total spend and write a sort order to DynamoDB.
Our GSI allows us to query for a company’s advertisement summaries. Once the base table has a sort_order_spend value written for each advertisement summary, if configured, our GSI will include the sort order for each summary. For example, our GSI would look like this:
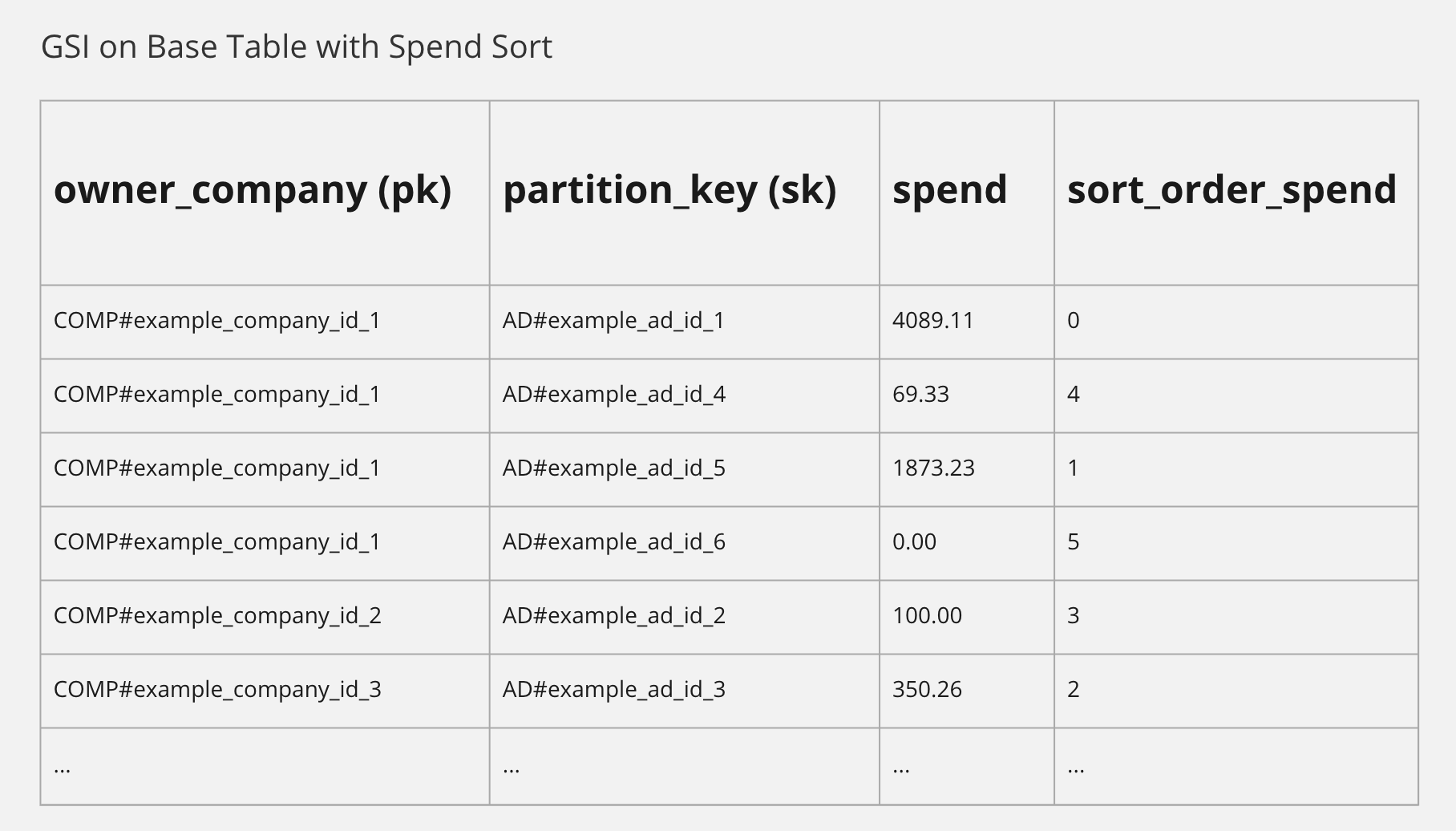
Beautiful. To get a company’s advertisements sorted by spend, simply query the GSI with an attribute range expression, as follows:
owner_company = COMP#example_company_id_1 AND sort_order_spend BETWEEN 0 AND 9
Assuming the results are paginated, depending on the current page and page size limit, we can send the correct range for the sort order spend. In our example, let’s say we are on the first page (0) and we are requesting 9 advertisements (at most). So, our range is 0 – 9.
We get our advertisements sorted by highest spend! We can get the sorted list by lowest spend by telling DynamoDB to scan the index in the opposite direction (ScanIndexForward: false).
That wasn’t so bad, right? Sure. Wait, a new requirement hot off the kanban board!
The advertisements must be sorted by either highest spend or impressions.
Ok, we’ve done this before. Add sort_order_impressions to our advertisement summaries and configure our GSI to include the field in our index. Not a biggie.
New requirement: the advertisements must be sorted by … ad nauseam.
This inflexibility, non-extendability, and manual pre-calculation is not a good choice for any application that requires flexible sorting.
Let’s make the situation significantly worse for DynamoDB by adding a requirement. Keep in mind, this requirement is table stakes for SaaS apps.
New requirement: users must be able to retrieve advertisements within a given time range.
Our pre-calculated advertisement summaries are worthless at this point. Our pre-calculated total spend and spend sort orders are worthless, as they are pre-calculated over a fixed time range. Any filtering of the time range (other than the exact same range as the data used for the pre-calc) will return incorrect sorting of the advertisements.
One option — pre-calculate every possible permutation of time ranges and their total spend values and sort order values. This is ridiculous and costly.
Let’s compound the issue with some more possible (standard) requirements:
Users must be able to filter advertisements by channel, media type, and time range.
Users must be able to retrieve advertisements for a given time range, across all companies.
Users must be able to combine sort types and filter types.
Users must be able to see aggregate and complex metrics across advertisements and companies.
…
If sorting, filtering, compound sorting-filtering, and slicin’ n’ dicin’ data is required for your use-case, I suggest avoiding DynamoDB. There are tried-n-true solutions for this use-case (e.g., Postgres, Redshift, etc.). These types of solutions provide DB-layer operations for aggregation, ad hoc filter and sort, whereas DynamoDB is just an API offloading those operations to the user outside of DynamoDB.
Though it is possible to use DynamoDB Streams to trigger code outside Dynamo on writes to your tables, and then aggregate/pre-calc at will, but I have found DynamoDB streams to be a band-aid across a gaping wound. If you find yourself using DynamoDB streams for complex aggregation, filtering, sorting, etc., please consider a tool designed for those use cases instead.
Beyond the non-starter limitations of DynamoDB for certain use-cases, there are some general annoyances I encounter when using DynamoDB (for all use-cases).
The Annoyances when DynamoDB
DynamoDB marshalls and un-marshalls data for a bunch of reasons (we will ignore here). The end result for the user is a pain in the ass. Manually converting all data types to strings and back each time across the wire is no fun. Dynamo has added some automatic converters, but they still must be used programmatically.
Next, DynamoDB has a limit on the response size for a given request. Large tables and/or items leads to truncated responses, which leads to malformed JSON, which leads to runtime parse errors.
Relatedly, during acquisition and pre-calculation of data, I often get throttled by the DynamoDB API, even when using batch writes.
Filter expressions are run as post-processing. Ugh, makes them almost useless. DynamoDB has to load all of the data from a query before filtering it.
Finally, and I think most importantly, the AWS documentation (in general) is horrendous. I’d rather read their source code than their documentation — scary.
So we do not lose sight of the major limitations of DynamoDB, let’s wrap.
Summary
Instead of trying to force all of your use-cases into DynamoDB, I offer one of my favorite aphorisms:
I mistrust all systematizers and avoid them. The will to a system is a lack of integrity.
— Friedrich Nietzsche (Twilight of the Idols)
Software doesn’t fit into a single system. We do ourselves a favor when we have the integrity to use the right tool for the right part of our system, even if it requires different concepts and abstractions. The polyglot data layer is still the one for me!
TL;DR — I propose a poly-persistence solution. One that uses DynamoDB for pre-calculating simple static data that requires performant reads. But, also a solution that uses SQL/an elastic slice-dice technology for dynamic, complex, detailed, aggregated, filtered, and sorted data.